How-To Implement DynamoDB Data Versioning (The Right Way)

Written by Charuka Herath
Published on April 25th, 2022
Time to 10x your DynamoDB productivity with Dynobase [learn more]
Amazon DynamoDB is a fully managed, cloud-native, NoSQL database service. It provides some amazing features to make developers' work easier. In this article, I will discuss how DynamoDB supports data versioning and different methods of implementing it.
What is Data Versioning in DynamoDB?
Data versioning in DynamoDB is a simple yet helpful concept. The DynamoDB table will have a new attribute to save the version when versioning is enabled. DynamoDB will assign a version when you first save a tuple, and it will increment the versions as you update the tuple.
When updating to a new version, the versioning concept is to create an entirely new item that uses the same partition key (which was in the previous version) and a different sort key. This ensures that all versions of the data are preserved and can be retrieved as needed.
When Should You Consider Data Versioning in DynamoDB?
The primary need for data versioning is to understand if a newer dataset version is available in an application.
Apart from that, there are use-cases such as:
- Tracking and saving data for machine learning models.
- Creating and switching between versions of data easily.
- Determining the versions of data used previously in research projects.
- Comparing data in scenarios like developing model metrics among experiments.
- Creating engineering tools and defining best practices in ML-based projects.
For example, consider a scenario where a researcher is researching to find a cure for COVID-19. During the research process, the researcher may have gone through different combinations of drugs. These combinations can be saved in a table as versions. As a critical requirement, the researcher needs to identify the latest and most accurate versions of the data out of millions of data combinations. Without proper versioning, handling these data is, of course, a nightmare.
Since now you understand the importance of versioning, let's see the different methods available to implement versioning in DynamoDB.
How-To Implement Data Versioning in DynamoDB
There are several ways to implement data versioning in DynamoDB. In this article, I will discuss the 3 most used data versioning methods in DynamoDB.
1. Maintaining 2 Separate Tables
As the name implies, 2 tables are used to keep track of the data version in this approach. Usually, these 2 tables are named the resource table and the resource history table.
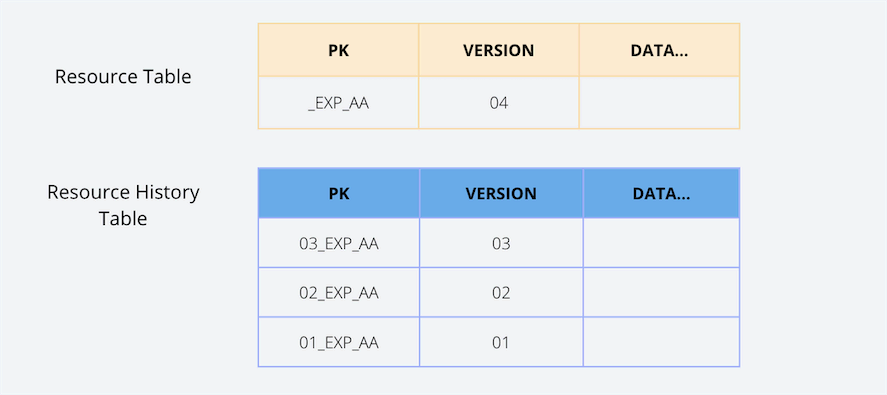
Resource Table
The resource table contains the latest version of each data tuple, and it has the following characteristics.
- The primary key (PK) is a partition key, and it is used to replace the data when a newer version is available.
- It consists of VERSION, which is an integer.
- Only has one row of data per PK.
Resource History Table
The resource history table contains all the data versions. Therefore, the table needs more storage. But the read capacity of the table will get lower when it grows. Apart from that, it has the following characteristics.
- The primary key (PK) is a composite key (PK+VERSION).
- It consists of VERSION, which is an integer.
- Has multiple data rows per PK.
Both tables will be updated when inserting, updating, and rolling back in this approach. According to the above example, data in the resource table will move to the resource history table as we update the data tuple.
However, the cost of implementing this approach is high since we need to maintain 2 tables.
2. Maintaining a Single Table for Versioning While Keeping a Metadata Table
Maintaining a single table is the perfect solution for a cost-effective versioning method. In this approach, developers can either version using numbers or timestamps.
But, before discussing them in detail, it is essential to understand the purpose of the metadata table. For example, consider a car manufacturing plant that uses assembled robots. (assume that one table represents a single robot)
A robot can have multiple statuses in the production lineup such as active, deactivate, power-down, malfunctioned, which are variable activities against the time. So these statuses can be identified as different versions of the robot. Also, there are data specific to a robot, such as power consumption, accuracy, and power input type. These specific data can be identified as metadata.
So, when it comes to DynamoDB, we can store all the non-version-related data in the metadata table.
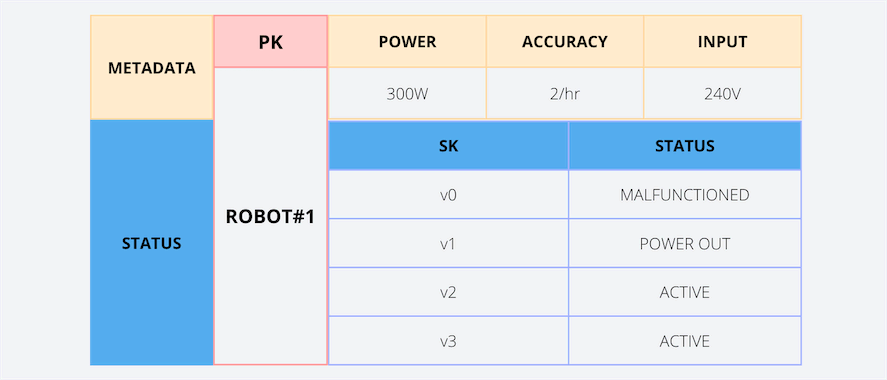
1. Versioning Using a Number
Using the sort key prefixes is the best design pattern to use in this approach for versioning. If we consider the robot example explained above, the primary key of each robot detail will be composed of the partition key (ROBOT#1) and a sort key (v0, v1, v2, v3).
When a new status data is inserted, the version number prefix (v0) is inserted as the sort key. When updating the status, you can use the next higher numeric value as the version prefix (v1, v2, v3, v4). So, we can always easily locate the latest version by referring to v0.
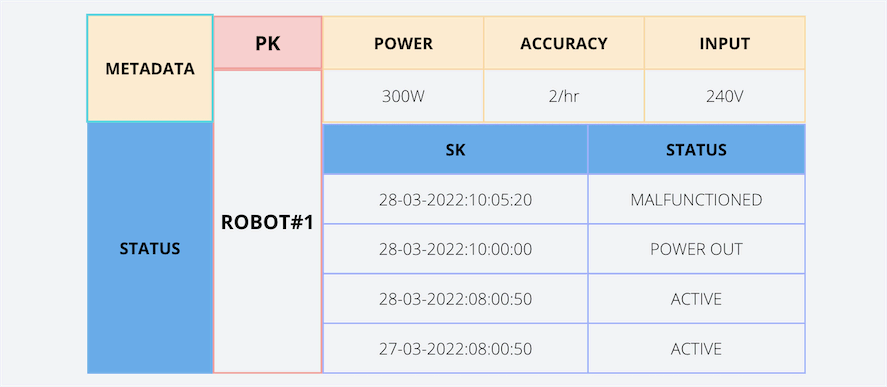
2. Timestamp Based Versioning
This is one of the common approaches used by many developers. The major difference in this approach is that it uses timestamps instead of using a number as the sort key. We can retrieve the latest version of the data by ordering the timestamp.
The following code shows how to store and retrieve the latest state data using Python:
3. Using Atomic Counters
An atomic counter is a numeric attribute that increments unconditionally. DynamoDB offers some operations that allow for updating values within an object in an atomic way. This approach is perfect when you have a quantity or counter, and you want to manipulate (decrease or increase) it without reading its value first.
Here, developers can use the UpdateItem operation to implement an atomic counter without interfering with other write requests.
For example, if you need to implement a banking application that records currency exchange rates, it can be easily designed using atomic counters. Here the rates can be taken as versions according to the requirements.
DynamoDB Data Versioning Best Practices
The main drawback of the separate table approach is the unorganized way of versioning. On the other hand, it is a straightforward approach to versioning your applications.
In a scenario where the version number is not provided in the update request, atomic counters can be useful. When using atomic counters, you do not need to get the latest value attribute for the updated item.
In the single table approach, selecting between the number-based versioning and the timestamp-based versioning is tricky.
In a scenario where the versions do not change rapidly, I suggest using the number-based approach since it is the most organized approach to historical data. Also, retrieving the latest version is much clearer as well.
However, in a situation where the versions change rapidly (e.g.: using a humidity sensor to check humidity levels in a controlled environment), timestamp-based versioning can be the best approach.
Additional Considerations for DynamoDB Data Versioning
When implementing data versioning in DynamoDB, it's important to consider the impact on read and write capacity units (RCUs and WCUs). Each versioning method has different implications for performance and cost. For instance, maintaining two separate tables can double the write operations, while a single table with a metadata table might be more efficient but could complicate queries. Additionally, consider implementing automated cleanup processes for old versions to manage storage costs effectively. Using DynamoDB Streams can also help in tracking changes and triggering actions based on data updates, which can be particularly useful in versioning scenarios.
FAQ
Does DynamoDB have versioning?
No, DynamoDB does not have versioning out of the box. Instead, you have to implement versioning using the different approaches explained in this article.
In DynamoDB, how can I implement versioning without replacing the previous record?
You can implement versioning without replacing the previous record by using Atomic counters. DynamoDB offers operations that allow updating values within an object in an atomic way. This approach is perfect when you have a quantity or a counter, and you want to manipulate (decrease or increase) it without reading its value first.