DynamoDB SLA - Everything You Need To Know

Written by Lahiru Hewawasam
Published on March 10th, 2022
Time to 10x your DynamoDB productivity with Dynobase [learn more]
Introduction
The SLA (Service Level Agreement) between Amazon DynamoDB and the customer applies to each account that uses the DynamoDB services. If there is a conflict between the terms of the AWS customer or other agreement governing the use of the DynamoDB services provided by AWS, the terms and conditions mentioned within the DynamoDB Service Level Agreement will apply (but only to the extent of a conflict).
This article will cover the information needed for you to understand the terms and conditions mentioned within the AWS DynamoDB Service Level Agreement and how these terms will affect your service usage.
Service Commitment
AWS states within their SLA that they will ensure DynamoDB will be operational by using reasonable efforts within a Monthly Uptime Percentage for each AWS region. The monthly uptime guaranteed within the Global Tables SLA is at least 99.999% (effectively a 5-minute downtime within a year) or within the Standard SLA is at least 99.99% (virtually a 52-minute downtime within a year).
Service Credits
If DynamoDB does not meet these service commitments, you will receive a Service Credit.
Service Credits calculations take place as a percentage of your charges for DynamoDB as the monthly billing cycle.
The Monthly Uptime Percentage for any given AWS region goes below the ranges mentioned in the table below.
However, if the Standard SLA applies, the service credits calculated would include the total charges paid for DynamoDB in the applicable AWS region. If the Global Table SLA applies, the service credits calculated would consist of the total charges paid for DynamoDB for the AWS region plus the charges applicable for Global Tables produced for corresponding replica tables in other AWS regions:
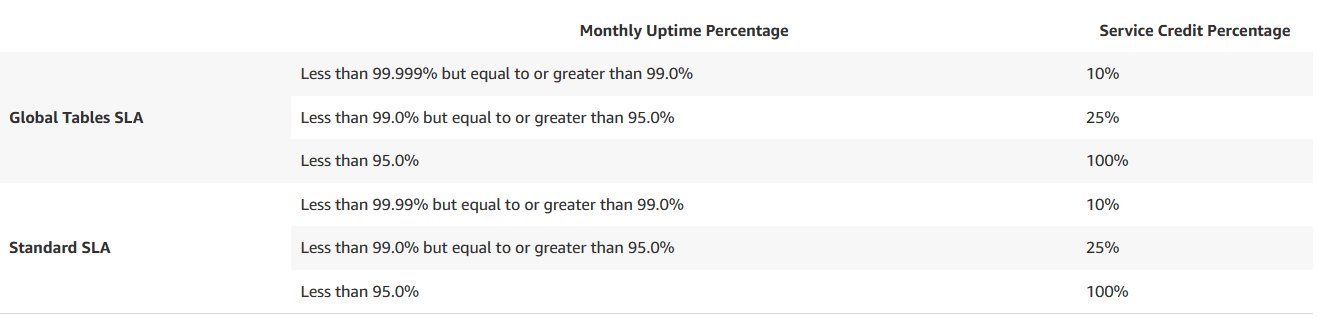
Latency
Developers can typically expect a single-digit millisecond latency; however, the latency can range between 10-20 milliseconds. Notably, strongly consistent reads will generally have a higher latency than eventually consistent reads. You would need to consider adding an add-on transparent caching layer such as the DynamoDB Accelerator (DAX) if the application you are building is a large-scale application requiring a latency of less than one millisecond. These additional services to improve latency add cost and possibly hinder data consistency and developer agility since the application would now have to deal with the additional complexity of populating the cache and keeping the cache consistent with the database.
DynamoDB Queries and Streams have the usual low latency that we've come to expect from AWS. However, there may be some rare delays when retrieving data via a query or waiting for a lambda to trigger based on a streams event; this may be due to a significant load on the AWS infrastructure.
DynamoDB recommends that no more than two processes read from a stream shard simultaneously; this will directly impact the performance of your application.
Eventual Consistency
AWS provides the DynamoDB service across multiple AWS regions worldwide, each region being independent and isolated from other AWS regions. You can refer to the complete list of AWS regions in which DynamoDB is available.
Every AWS region consists of multiple distinct geolocations known as Availability Zones. Each Availability Zone operates independently of other Availability Zones and provides inexpensive, low-latency network connectivity to different Availability Zones in the same region. In addition, it allows rapid replication of your data among multiple Availability Zones in a Region.
The write completes when data is written to a DynamoDB Table and receives an HTTP 200 response. Usually, it takes one second or less until the data is eventually consistent across all storage locations.
Eventually Consistent Reads
When reading data from a DynamoDB table, the response might not reflect some updated results from recently completed write operations. However, suppose you repeat the read request after a short time. In that case, the response should return the latest data due to the time taken for DynamoDB to replicate the data across multiple Availability Zones and regions.
Strongly Consistent Reads
DynamoDB responds with the most up-to-date data when you request a strongly consistent read; these results will reflect the last successful write operations updates. However, it comes with some disadvantages:
- Network outages or delays may disrupt and strongly consistent read operations.
- Eventually consistent reads may have lower latency than strongly consistent reads.
- Global secondary indexes do not support strongly consistent reads.
- Eventually consistent reads use less throughput capacity than strongly consistent reads.
It is important to note that DynamoDB will use eventually-consistent reads unless you specify otherwise.
Security
When you start using AWS DynamoDB, security responsibilities become shared between you and the cloud service provider. In this case, AWS is responsible for securing the underlying infrastructure that runs the cloud, and you are responsible for any data you choose to store on the cloud.
AWS is responsible for protecting and securing the global infrastructure that runs all the services (including DynamoDB) in the AWS cloud; this includes the security configurations of DynamoDB and any other managed services products.
However, you are responsible for managing credentials and user accounts that you create or that come by default. You are also responsible for any security-related settings that you may change on a table or any other entity related to the DynamoDB service. For example, it means that you would be responsible for lowering the security standards if you disable encryption on a DynamoDB table or apply an insecure encryption mechanism.
TTL (Time to Live)
Time to Live is a function available within DynamoDB to remove any item within a table after a set amount of time. The significance of this function is that it deletes the entry without consuming any write throughput. It is helpful when used to reduce stored data volumes by retaining only the items that remain current for the workload's needs.
The following are example Time to Live use cases:
- Remove unwanted transaction data after a specific time.
- Retain sensitive information only for a certain amount of time according to contractual or regulatory obligations.
DynamoDB deletes the expired items within 48 hours of expiration. However, items that have expired but not expired by Time to Live will still appear in queries, reads, and scans. If you want to filter out these expired items, you can use a filter expression that'll return the items with a greater value than the current time. The time format you use within the filters must be in epoch format. You may refer to the Filter Expressions for Scan for more information.
Backup and Restore
DynamoDB provides robust backup and restore capabilities to ensure data durability and availability. You can create on-demand backups or enable continuous backups using DynamoDB's Point-in-Time Recovery (PITR) feature. On-demand backups allow you to create full backups of your tables for long-term retention and compliance purposes. PITR, on the other hand, enables you to restore your table to any point in time within the last 35 days, providing a safety net against accidental writes or deletes. These features are crucial for disaster recovery and maintaining data integrity.
Conclusion
In this article, I've covered the basic concepts of AWS DynamoDB Service Levels and what you need to know before starting your subscription. Additionally, we explored the importance of latency, consistency models, security responsibilities, and the TTL feature. We also introduced the backup and restore capabilities that are essential for data durability and disaster recovery.
I hope you have found this helpful. Thank you for reading!
Frequently Asked Questions
How is DynamoDB SLA calculated when using multiple availability zones?
We can use composite SLA to calculate the SLA when using multiple availability zones. For example, if you were to use Availability Zone 'A' with an uptime of 99.95%, Availability Zone 'B' with an uptime of 99.90%, and Availability Zone 'C' with an uptime of 99.99%, the calculation would look something like this:
Combined SLA = Availability Zone 'A' SLA x Availability Zone 'B' SLA x Availability Zone 'C' SLA
Combined SLA = 99.95% x 99.90% x 99.99%
Combined SLA = 99.84%