DynamoDB + Serverless Stack - The Ultimate Guide w/ Examples

Written by Mahesh Samarasinghe
Published on July 3rd, 2022
Time to 10x your DynamoDB productivity with Dynobase [learn more]
DynamoDB is a fully managed, serverless, key-value and document database service introduced by AWS. Its impressive integration with AWS Lambda functions has made it super easy to implement an API. But with the growing business needs, replicating these infrastructures has become a common requirement, and Infrastructure as Code (IaC) has become very popular. Serverless Stack (SST) is one such tool that can be used to maintain your infrastructure as code.
What is Serverless Stack (SST)?
Serverless Stack is a framework built on AWS CDK, enabling users to implement and maintain their infrastructure as code. SST enables its users to:
- Implement infrastructure using AWS CDK.
- Test applications live using Live Lambda Development.
- A web-based dashboard to manage the applications.
Due to the simplicity, ease of use, easy maintenance, and seamless integration with AWS services, it is a great option for maintaining database and application infrastructure.
So, let's implement a DynamoDB database and a Rest API using SST to get a better understanding.
Demonstration
Step 1: Prerequisites
- Node.js >= 10.15.1
- AWS account configured with AWS CLI locally.
Step 2: Create a New Serverless Stack Project
To create a new SST project, we can use the following npx command.
Note that we are using TypeScript for this demonstration. Once the project has been created, make sure to run npm install to install all the dependencies.
Step 3: Setup Blog Table
The below code snippet can be used to create a new table named Blog in DynamoDB. You need to add this snippet to the initially defined stack in the MyStack.ts file located in the stacks folder.
Step 4: Setup API CRUD Operations
Next, you need to add the necessary CRUD operations for the table. For that, define the routes and required environment variables for the CRUD operations. To define the routes, add the following code snippet inside the same stack where the DynamoDB table was defined.
Finally, your stack should look like the below.
List All Blogs
To create the endpoint to list all blogs, you need to create a new file under the functions folder and add the following code snippet to define the Lambda function. It will scan and fetch all the available blogs from the database.
Note that scan is a heavy operation performed on the database. Therefore, you need to maximize the performance by defining a sort key along with the partition key, using a composite key as the primary key, and using the partition key to narrow down and list the search results.
Create a Blog
Create another new file under the functions folder and update it with the below code to create the endpoint for creating blogs.
Get Blog by Id
To implement the endpoint to fetch a blog post by its Id, create a new file under functions and add the following code snippet.
Update a Blog
To create the endpoint to update a blog, add the following code snippet in a new file under the functions folder.
To create an endpoint to delete a blog, create a new file under the functions folder and insert the following code snippet. If the present parameters are going to be dynamic UpdateExpression and ExpressionAttributeValues have to be generated dynamically.
Delete a Blog
To create an endpoint to delete a blog, create a new file under the functions folder and insert the following code snippet.
Step 5: Deploy and Test
SST provides a live Lambda web dashboard, making it easy to test and debug the application live. To test, you need to run npm start. Then the application will initially create the necessary AWS infrastructure. So initially, it will take some time. But after the initial start, the application will build and deploy quickly.
After that, each endpoint can be invoked and tested using the live Lambda dashboard, as shown in the image below.
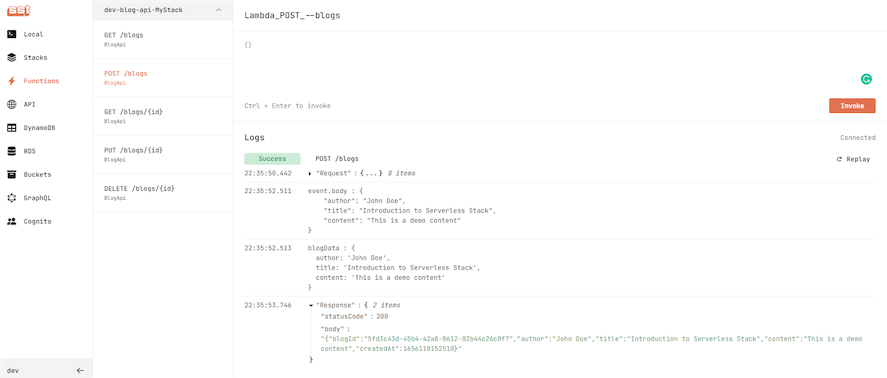
Conclusion
This article looked at implementing and managing a simple API with DynamoDB and Lambda functions via Serverless Stacks. We created endpoints to access the database and update the data accordingly. Complete code for the above example can be found in this GitHub repository.
Hope you have found this article helpful. Thank you.
Additional Considerations
When working with DynamoDB, it's important to consider the read and write capacity units (RCUs and WCUs) for your tables. These units determine the throughput capacity of your DynamoDB tables and can impact performance and cost. Additionally, DynamoDB supports various data types, including strings, numbers, binary data, and more complex types like lists and maps. Understanding these data types and how to use them effectively can help optimize your database design. Finally, DynamoDB offers features like Global Tables for multi-region replication and DynamoDB Streams for real-time data processing, which can be valuable for building scalable and resilient applications.