DynamoDB Joins [A How-To Guide]

Written by Lakindu Hewawasam
Published on April 17th, 2022
Time to 10x your DynamoDB productivity with Dynobase [learn more]
Join in DynamoDB - What You Need To Know
Most of us are accustomed to using normalized SQL databases to manage relational data. It helps avoid data redundancy and offers simple queries such as the join to combine this data using the defined foreign keys.
A join query aggregates results from two or more tables based on one related piece of information (foreign key). Since DynamoDB is a NoSQL database, it does not allow you to perform "join" queries on multiple tables.
A join requires the DBMS to scan several tables and perform complex processing to aggregate the data to return a result set. DynamoDB was built to provide quick, single-digit millisecond responses no matter how big the dataset. However, since joins do not scale well, DynamoDB chooses not to support it.
However, application developers require the capability of joins to retrieve aggregated results with a single API call. DynamoDB allows you to mimic a "join" by modeling the data with the single table design principle.
How Does DynamoDB Perform a Join?
Single Table Design
DynamoDB allows developers to mimic a join with the single table design principle. You can use the single table design to store all your application entities in one single table and use generic "primary key" attributes (e.g., PK, SK) to query the data based on your access pattern. Therefore, this allows developers to model complex one-to-many and many-to-many relationships in a single table while allowing quick lookup times via single queries.
Modeling Relational Data in DynamoDB with the Single Table Design (Using the Primary Key + Query API)
To get a better understanding, let's model a one-to-many relationship in DynamoDB and look at how we can mimic a join query by implementing the single table design.
Consider the following scenario:
- An organization has many users.
- A user belongs to one organization.

Figure 01: Sample One-to-Many relationship
We will use one DynamoDB table to store both the Organization and User entity, as it will enable easier access patterns. Therefore, I will design and create a table with a generic primary key using the single table designer offered by Dynobase.

Figure 02: Defining a sample model for the single table design.
Figure 02 illustrates the generic PK and SK names to map the partition and sort key. It removes the coupling between the keys and the type of entity that persisted in the table. We can then use the primary key and the query API to query the required data.
Additionally, an entity type attribute name is defined to easily distinguish the type of each entity persisted in the single table.
When storing data in a single table, you can use the pound sign (#) to prepend the entity type for the partition key value. It ensures that the same partition key does not override entities of various kinds.
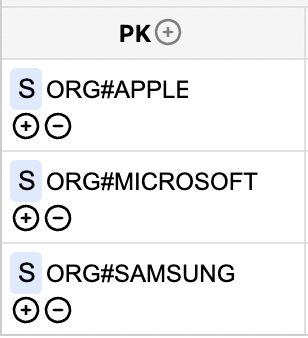
Figure 03: Mapping the Partition Key
Figure 03 illustrates the recommended way to map the partition key for an item in the single table design. It helps DynamoDB store the "item collection" in the same partition so that it can get queried by DynamoDB easier.
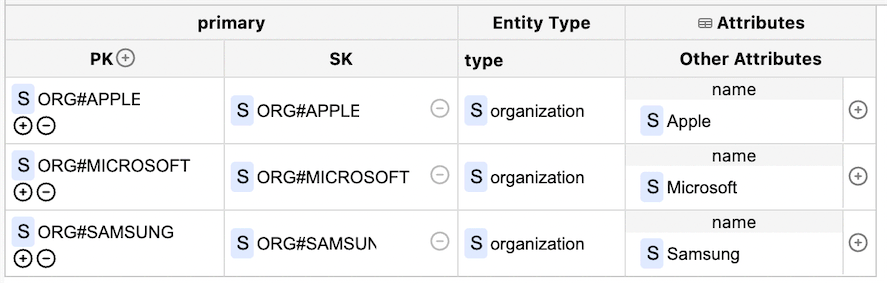
Figure 04: Inserting an Organization into the table
After understanding the use of the partition key convention, we can start inserting organization information into the table. I've added three organizations named "Facebook," "Microsoft," and "Samsung" which have the partition and sort key of "ORG#FACEBOOK", "ORG#MICROSOFT ", and "ORG#SAMSUNG". The sort key is the primary key to ensure only the organization can get queried.
Additionally, the "Entity Type" for each item is marked as "organization" to help visualize the data model.
The next part is to model the one-to-many relationship.
Traditionally, we would add a foreign key ("organizationId") to the user. But with the single table design, we could create an entry with the partition key - "ORG#ORG_NAME" and sort key - "USER#USER_NAME."
Consider the example shown below.
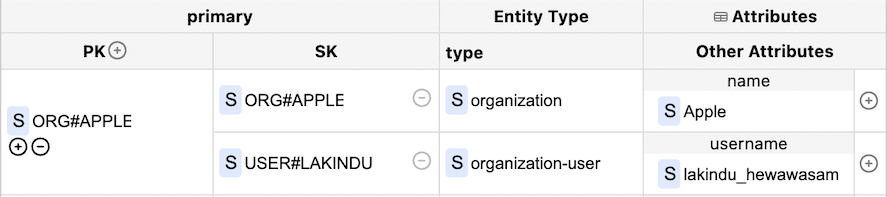
Figure 05: Assigning a User to the Organization
In figure 5, a new item with the sort key "USER#LAKINDU " is inserted with the partition key "ORG#APPLE". This means a user gets created for a particular organization. Likewise, we can insert many users into the organization, as shown below.
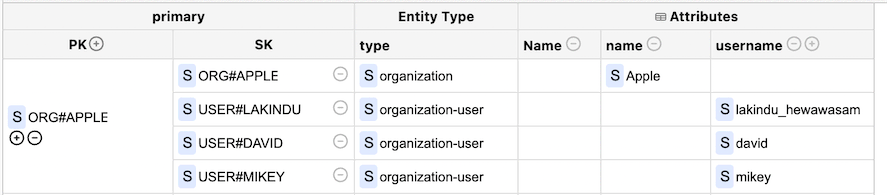
Figure 06: Creating the Single Table Design for the data
We've provided a sort key for each user with the prefix "USER#" to enable easy querying. We've created two access patterns for the User entity by doing so.
- Fetch information of all users in the organization.
- Fetch information of a single user in the organization.
This is possible because of the way we've modeled the primary key. Therefore, you must model your data in this way to mimic "join" queries.
I've declared the two access patterns using Dynobase.
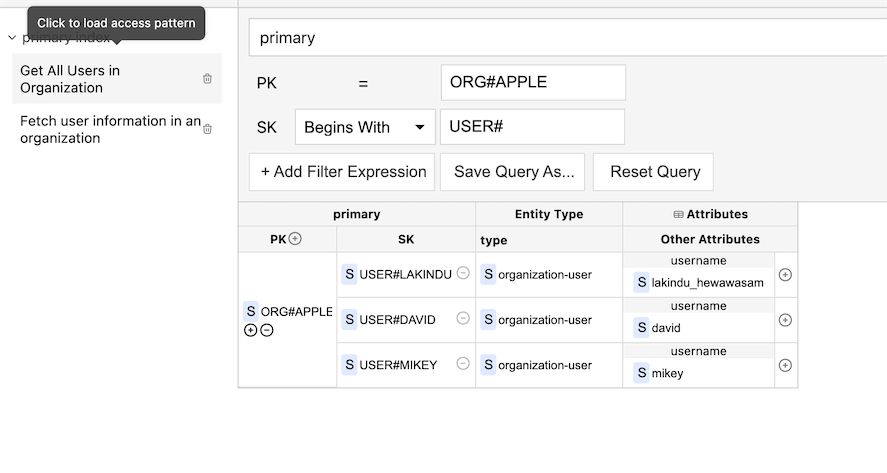
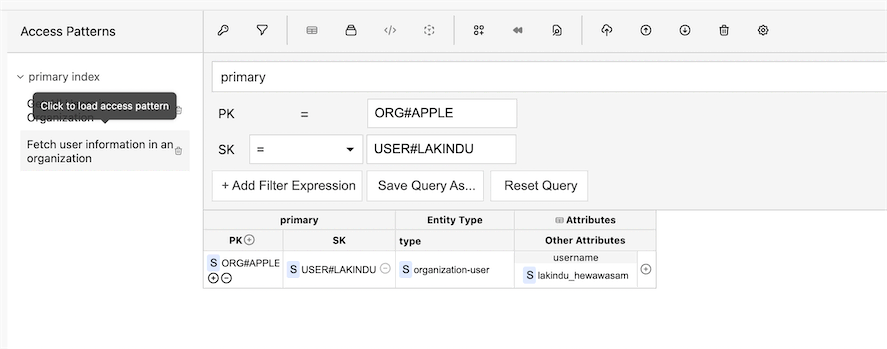
Figure 07: Defining the Access Patterns using Dynobase
Now, we can query the data with the partition key and the sort key (using the begins_with operator) to retrieve aggregated data. With this, we've successfully modeled our data to mimic a join.

Figure 08: Viewing the Aggregated Tabular Results
Figure 08 illustrates the item collections that we can readily fetch with our composite key. We can fetch all organizations and organization users.
Querying the Modeled Data
After successfully modeling the relational data in a single table, we can now query this data. The snippets below show some of the queries that we can do.
Querying Organization Information
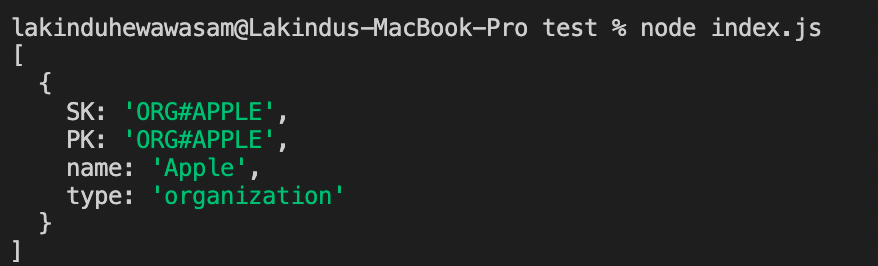
Figure 09 - Query result: Querying a single organization
The snippet shown above fetches information regarding a single organization. By providing the same value for both partition and sort key, DynamoDB can query the single organization information.
Fetching All Users In An Organization
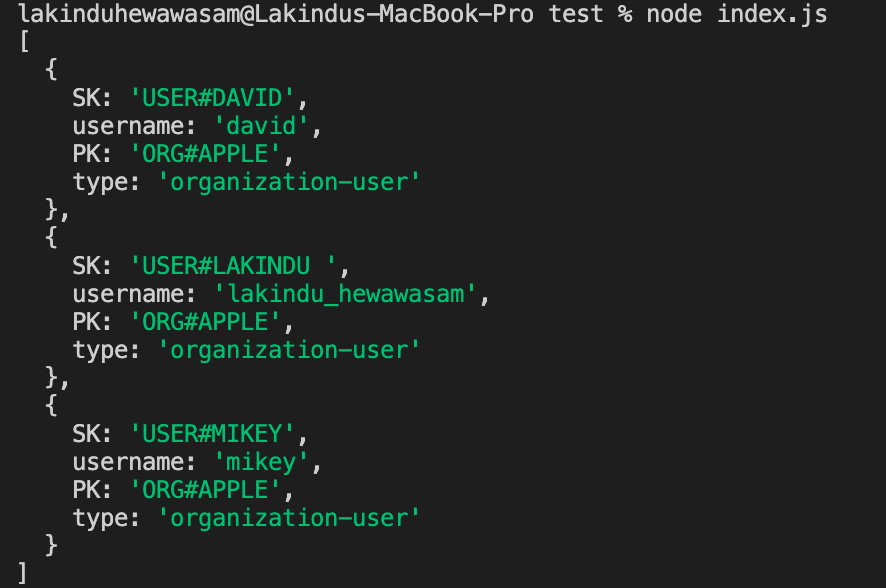
Figure 10 - Query result: Querying all users in the organization via a Join mimic.
The snippet above shows a query to fetch all users in the organization. Theoretically, this query shows the functionality of a SQL join as we've aggregated results of two entities by using a common attribute (Organization Name).
Fetching a Single User In an Organization
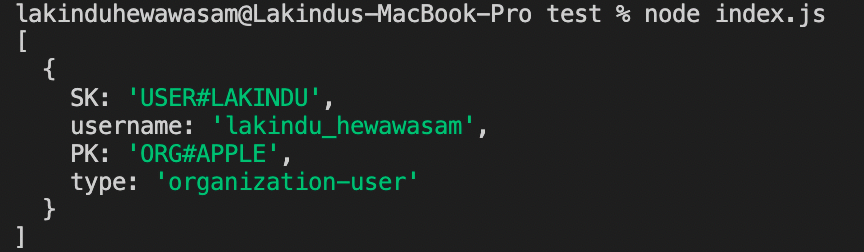
Figure 11 - Query result: Querying a single user in an organization
Figure 11 shows an extension of the query that we saw earlier. It uses "=" instead of "begins_with" as the sort key comparison operator to fetch information regarding a single user.
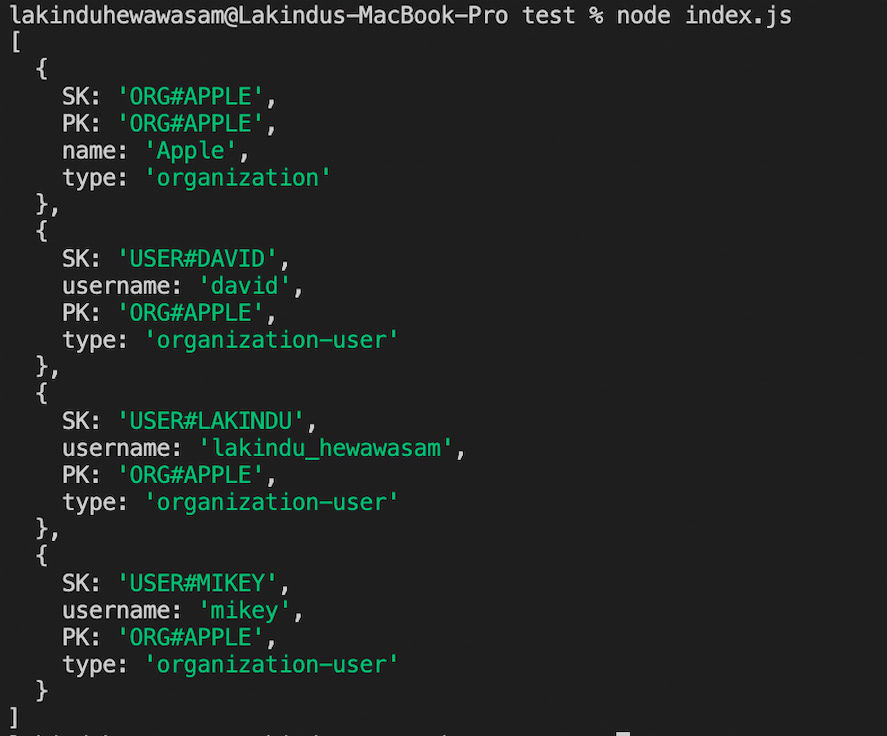
Figure 12 - Query result: Querying all users and the organization
Finally, we can get organizational information from all users by not specifying the sort key.
The above examples show the combination of queries we can perform when the single table design is appropriately implemented. Furthermore, it provides a way to effectively emulate the SQL join in DynamoDB via one table.
Therefore, the single table design principle is the recommended way of modeling relational data in DynamoDB.
DynamoDB Join Performance
Performing joins with DynamoDB is much faster than a traditional SQL database for two main reasons.
1. Reduced API Calls
Using a single table reduces the number of API calls for the access pattern, thus reducing the data retrieval latency.
2. Improved Query Performance due to Partition Optimization
The single table design used partition keys like "ORG#ORG_NAME" and sorts keys like "#ORG#ORG_NAME" or "USER#USER_NAME." When the items get persisted to DynamoDB, the partition key is passed through a hash function to determine the partition to store the data. It allows us to store the group of related data in one partition.
Therefore, when the data gets queried, DynamoDB can obtain the entire item collection from the same partition, thus creating faster query times for the join operation.
These reasons make DynamoDB joins far more performance effective and scalable when compared to SQL joins.
Best Practices for Single Table Design
When implementing a single table design in DynamoDB, it's crucial to follow best practices to ensure optimal performance and scalability. One important practice is to carefully plan your access patterns before designing your table. This involves understanding how your application will query the data and structuring your primary keys accordingly. Additionally, using composite keys effectively can help in creating efficient query patterns. Another best practice is to leverage Global Secondary Indexes (GSIs) to support additional query requirements without duplicating data. Finally, regularly monitoring and optimizing your table's performance using AWS CloudWatch and DynamoDB's built-in metrics can help in maintaining efficient operations.
Conclusion
Performing joins is not something that DynamoDB supports due to the performance issues that arise with scalability. However, DynamoDB uses the single table design as a more scalable and improved way of handling and querying relational data with no performance overhead.
I hope this article provided you with the information that you need to model relational data and query it effectively using DynamoDB.
Thank you for reading.
FAQ
Can DynamoDB do joins?
No. Joins are resource-intensive queries that do not scale well as your database grows in size. Therefore, DynamoDB does not allow "join" queries. However, it is possible to perform joins on DynamoDB tables via external services such as Apache Hive and Amazon EMR. But it's important to note that DynamoDB does not natively support joins.
Can DynamoDB store relational data?
Yes. Even though DynamoDB is a NoSQL Database, it allows developers to model and store relational data via the single table design.
How does DynamoDB manage relational data?
DynamoDB manages relational data in a single table with generic primary keys (can be a composite key). It then uses the primary key to query the data based on the access pattern. To perform additional queries, you can use Inverted Indexes or GSIs to enhance access patterns for relational data.
How does DynamoDB handle many-to-many relationships?
DynamoDB can model a many-to-many relationship by using the Adjacency List Design Pattern.